 关于rancher集群的高可用的实验
关于rancher集群的高可用的实验
因为前边部署的已经是ha的rancher集群,在三个节点前边,已经通过nginx代理,完成集群的ha状态。
这个时候,如果某个节点宕机,是不会影响整个集群的使用的。
这里模拟其中一个node关机。
目前三个节点分别是:
192.168.106.3
192.168.106.4
192.168.106.5
1
2
3
2
3
此时,把192.168.106.5shutdown关机,然后看整个集群的状态。
[rancher@localhost ~]$ kubectl get node
NAME STATUS ROLES AGE VERSION
192.168.106.3 Ready controlplane,etcd,worker 1h v1.11.6
192.168.106.4 Ready controlplane,etcd,worker 1h v1.11.6
192.168.106.5 NotReady controlplane,etcd,worker 1h v1.11.6
1
2
3
4
5
2
3
4
5
web管理界面在这中间可能有三到五分钟的反应时间,等待之后,去界面看看状态。
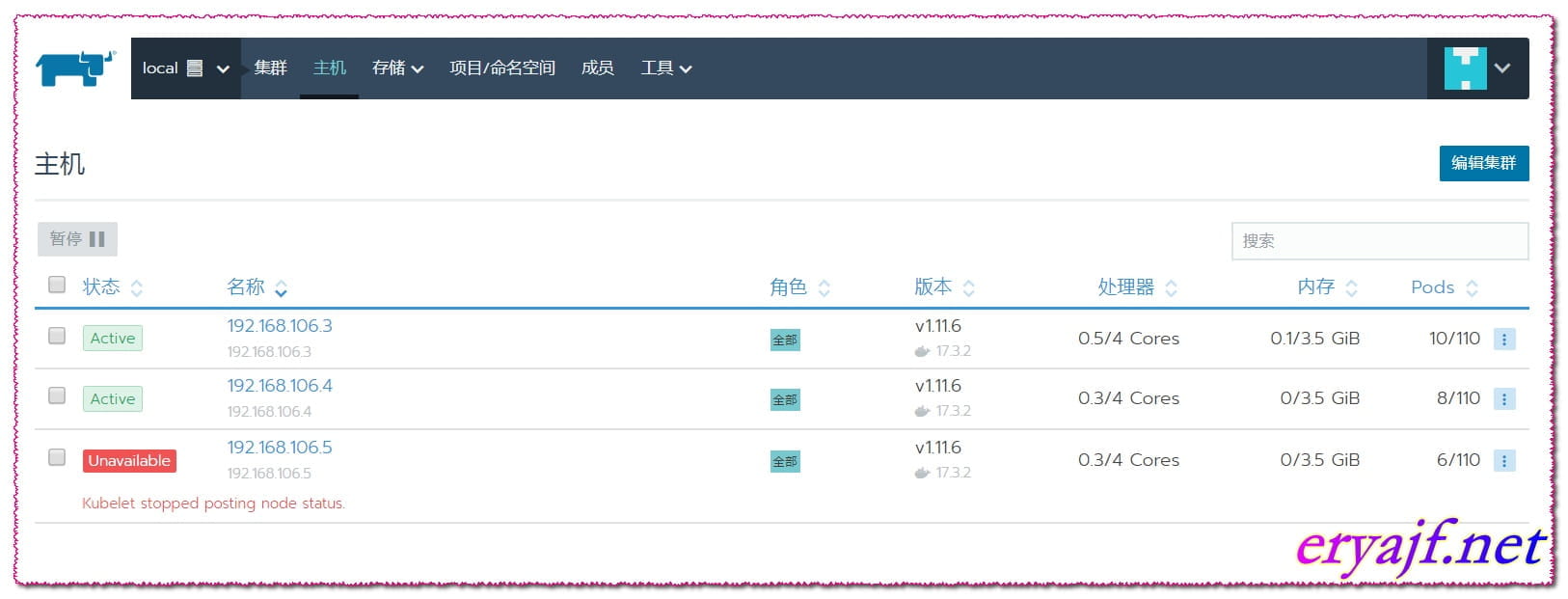
看到192.168.106.5状态异常,但是并不影响整个集群的使用。
因此,推荐使用这种ha集群进行管理。
现在再将192.168.106.5主机启动,然后回到集群查看状态。
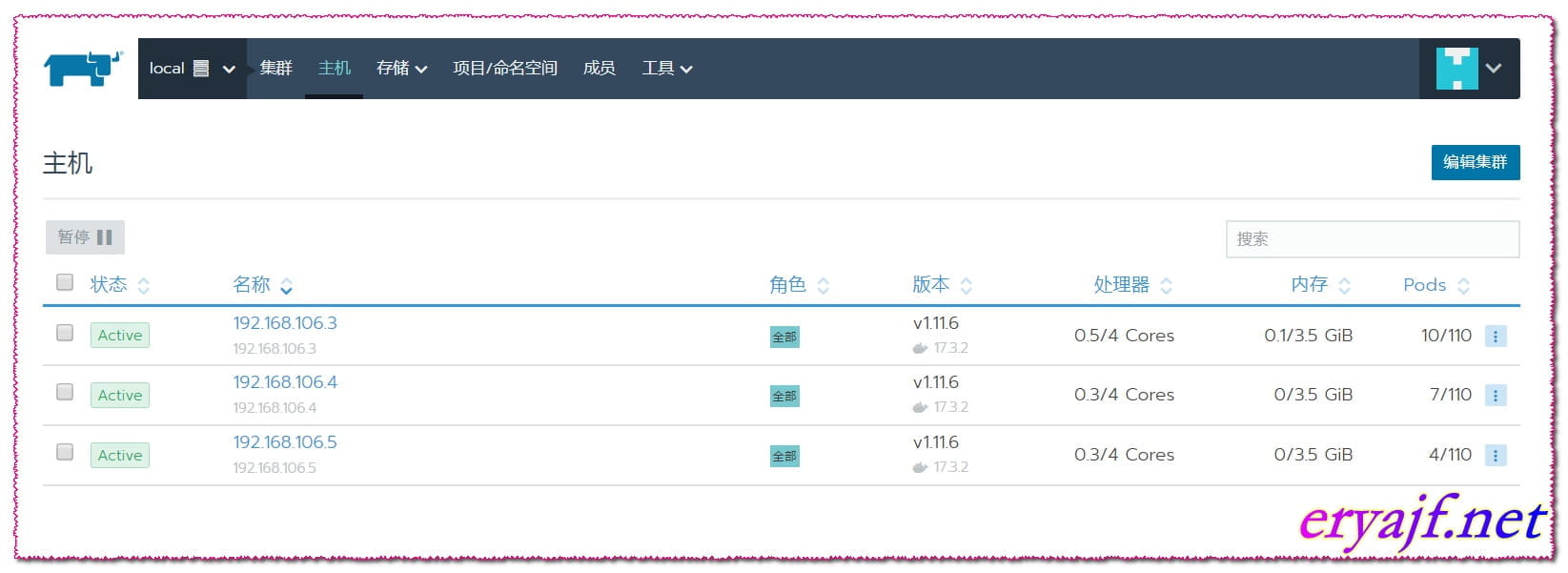
又一次回到了集群的怀抱之中。
更新时间: 2023/7/27 18:48:21